![]()
As my Music Tools project progressed, I found myself with a cloud environment and a growing dataset of my listening habits to explore. Spotify provides audio features for all of the tracks on its service. These features describe qualities about the track such as how instrumental it is, how much energy it has. I wanted to investigate whether the features that describe my larger genre-playlists were coherent enough to use as the classes of a classifier. I compared the performance of SVM’s with shallow multi-layer perceptrons.
All of these investigations are part of my listening-analysis repo, the work is spread out over a couple of different notebooks
analysis
Link to heading
Introducing the dataset, high-level explorations including average Spotify descriptor over time and hours per day of music visualisations
artist, album, track, playlist
Link to heading
Per-object investigations such as how much have I listened to this over time, it’s average descriptor and comparisons of the most-listened-to items
playlist classifier (SVM/MLP)
Link to heading
Investigations into whether my large genre-playlists can be used as classes for a genre classifier. Comparing and evaluating different types of support-vector machine and neural networks
stats
Link to heading
Dataset statistics including the amount of Last.fm scrobbles that have an associated Spotify URI (critical for attaching a Spotify descriptor)
On This Page Link to heading
1 Dataset
2 Playlist Classifier
- Class Weighting
- Data Stratification
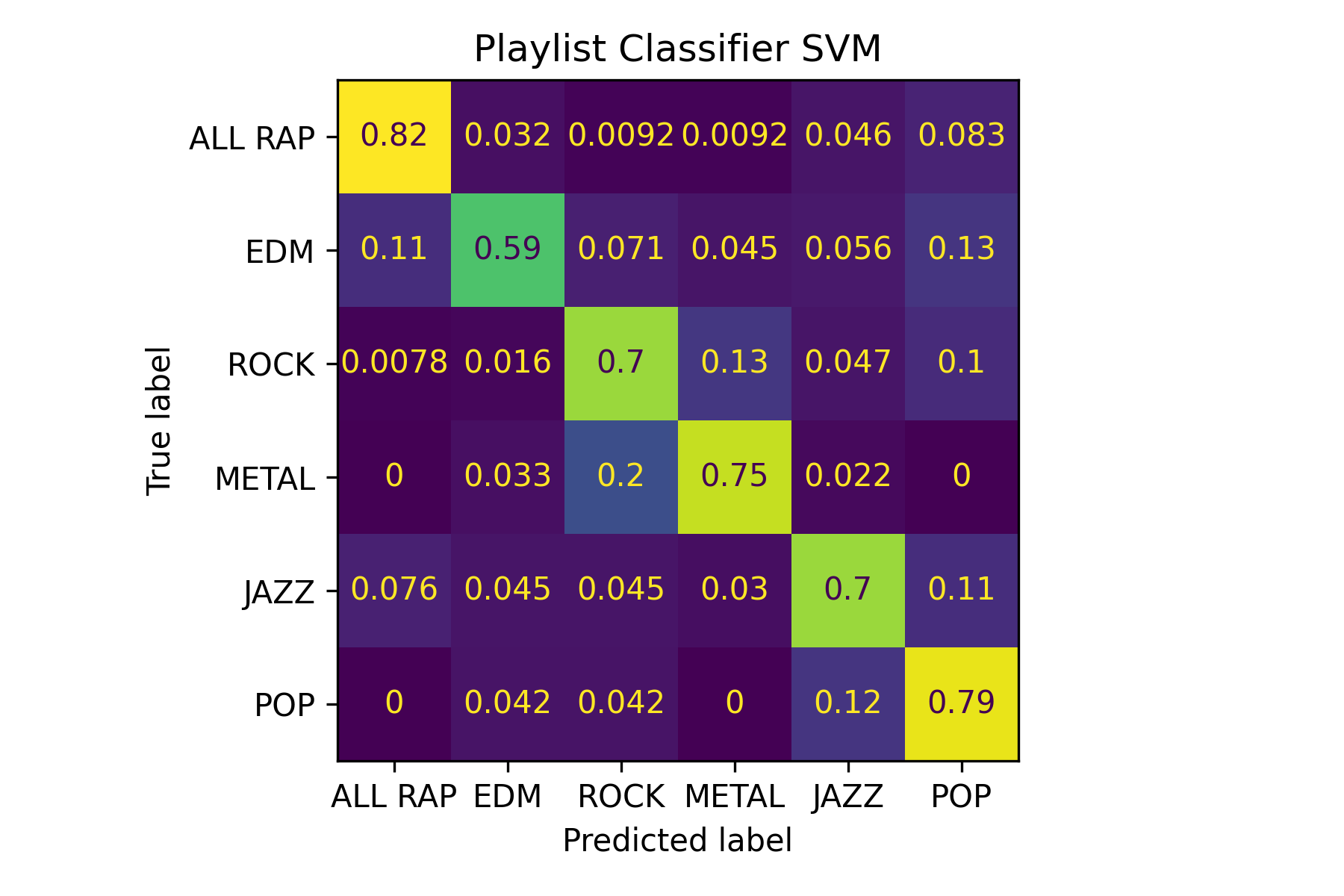
Confusion matrix for a SVM playlist classifier
Dataset Link to heading
The dataset I wanted to explore was a combination of my Spotify and Last.fm data. Last.fm records the music that you listen to on Spotify, I’ve been collating the information since November 2017. Spotify was used primarily for two sources of data,
1 Playlist tracklists
- Initially for exploring habits such as which playlists I listen to the most, the data then formed the classes for applied machine learning models
2 Audio features
- For each track on the Spotify service, you can query for its audio features. This is a data structure describing information about the track including the key it’s in and the tempo. Additionally, there are 7 fields describing subjective qualities of the track including how instrumental a track is and how much energy it has
These two sides of the dataset were joined using the Spotify URI. As the Last.fm dataset identifies tracks, albums and artists by name alone, these were mapped to Spotify objects using the search API endpoint. With Spotify URIs attached to the majority of my Last.fm scrobbles, these scrobbles could then easily have their Spotify audio features attached. This was completed using Google’s Big Query service to store the data with a SQL interface.
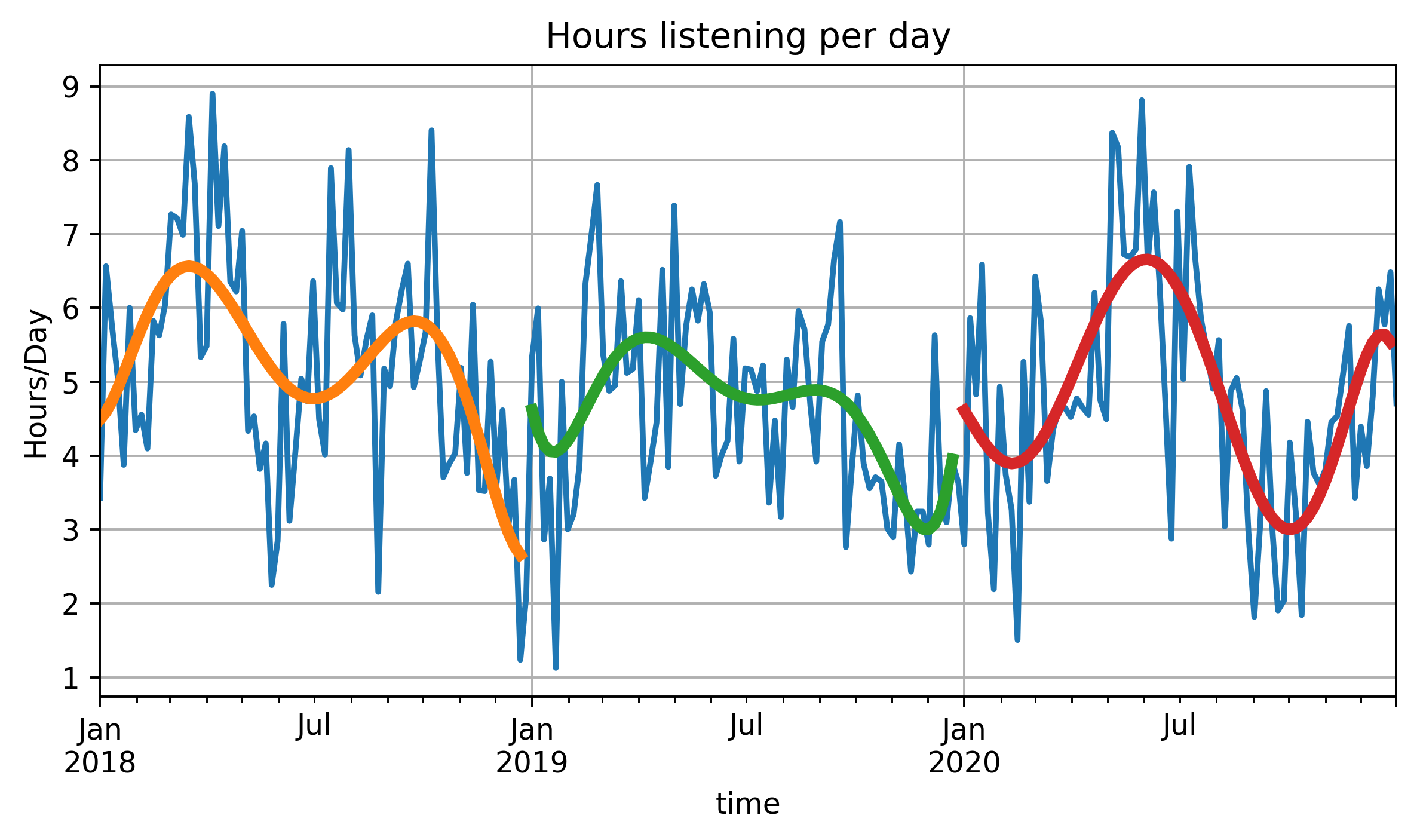
Average time spent listening to music each day. Per-year polynomial line of best fit also visualised
Playlist Classifier Link to heading
My large genre playlists describe my tastes in genres across Rap, Rock, Metal and EDM. They’re some of my go-to playlists and they can be quite long. With these, I wanted to see how useful they could be from a classification perspective.
The premise was this: could arbitrary tracks be correctly classified as one of these genres as I would describe them through my playlist tracklists.
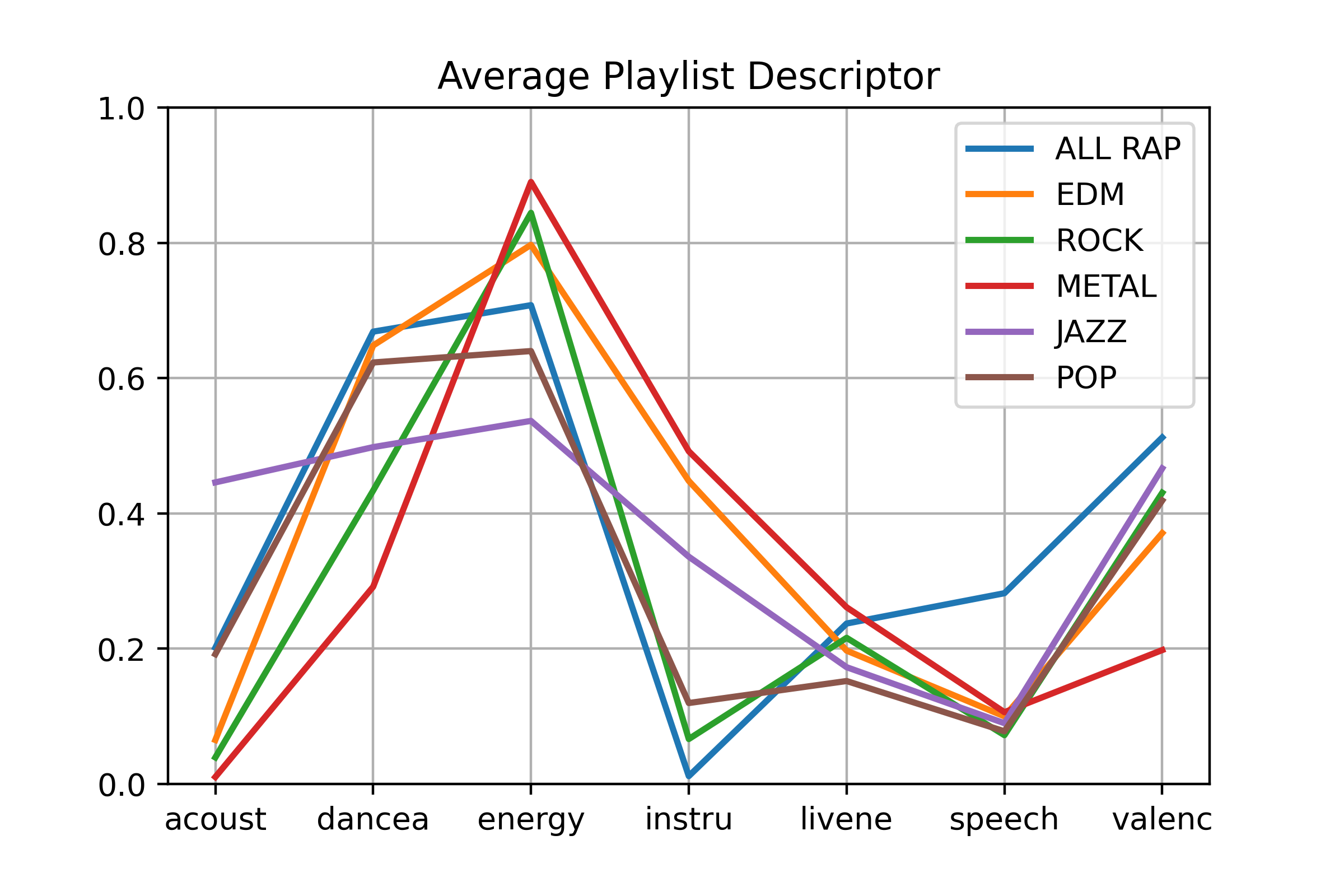
Average Spotify descriptor for each genre playlist being investigated and modelled
The scikit-learn library makes beginning to explore a dataset using ML models really fast. I began by using a support-vector machine. SVMs of differing kernels were evaluated and compared to see which type of boundaries best discriminated between the genres. The differences can be seen below,
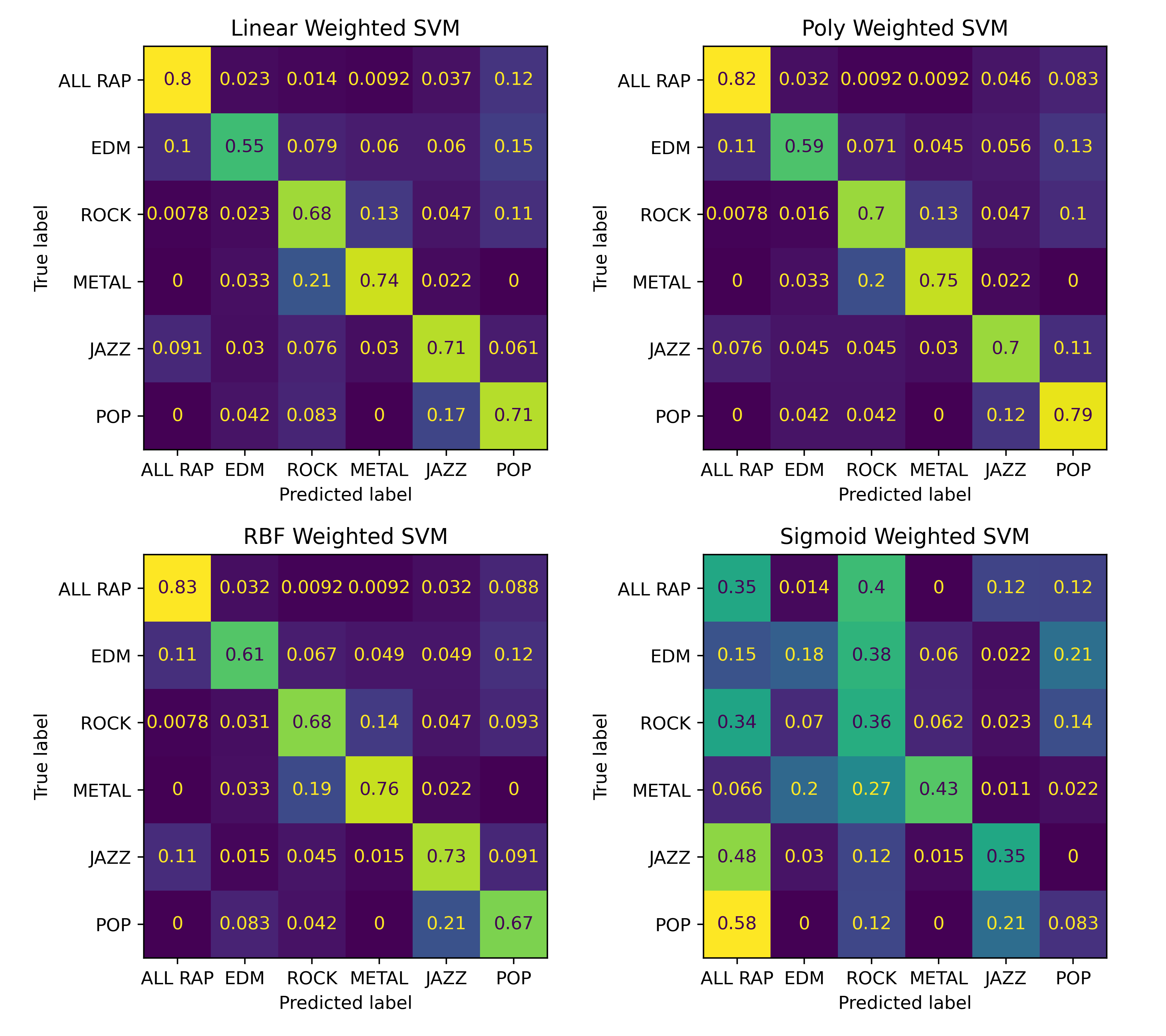
Confusion matrices for the different type of SVM evaluated
| SVM Kernel | RBF | Linear | Poly | Sigmoid |
|---|---|---|---|---|
| Accuracy, % | 71% | 68% | 70% | 29% |
.score() for each SVM model
Link to heading
From these, it can be seen that the Radial Basis Function (RBF) and polynomial kernels were the best performing with the Sigmoid function being just awful. When implementing one of these models in Music Tools playlist generation, these two kernels will be considered.
Class Weighting Link to heading
The playlists that I’m using aren’t all of the same length. My Rap and EDM playlists are around 1,000 tracks long while my Pop playlist is only around 100. This poses an issue when attempting to create models from these playlists. The Rap model, for example, will be a much larger model than the Pop playlist and take up more volume in the descriptor space. This can make it much harder to correctly classify tracks as these under-represented classes when larger ones dominate.
This issue can be seen visualised below, in the left matrix no tracks were correctly classified as Pop. Instead, half were classified as EDM and 20% as Rock.
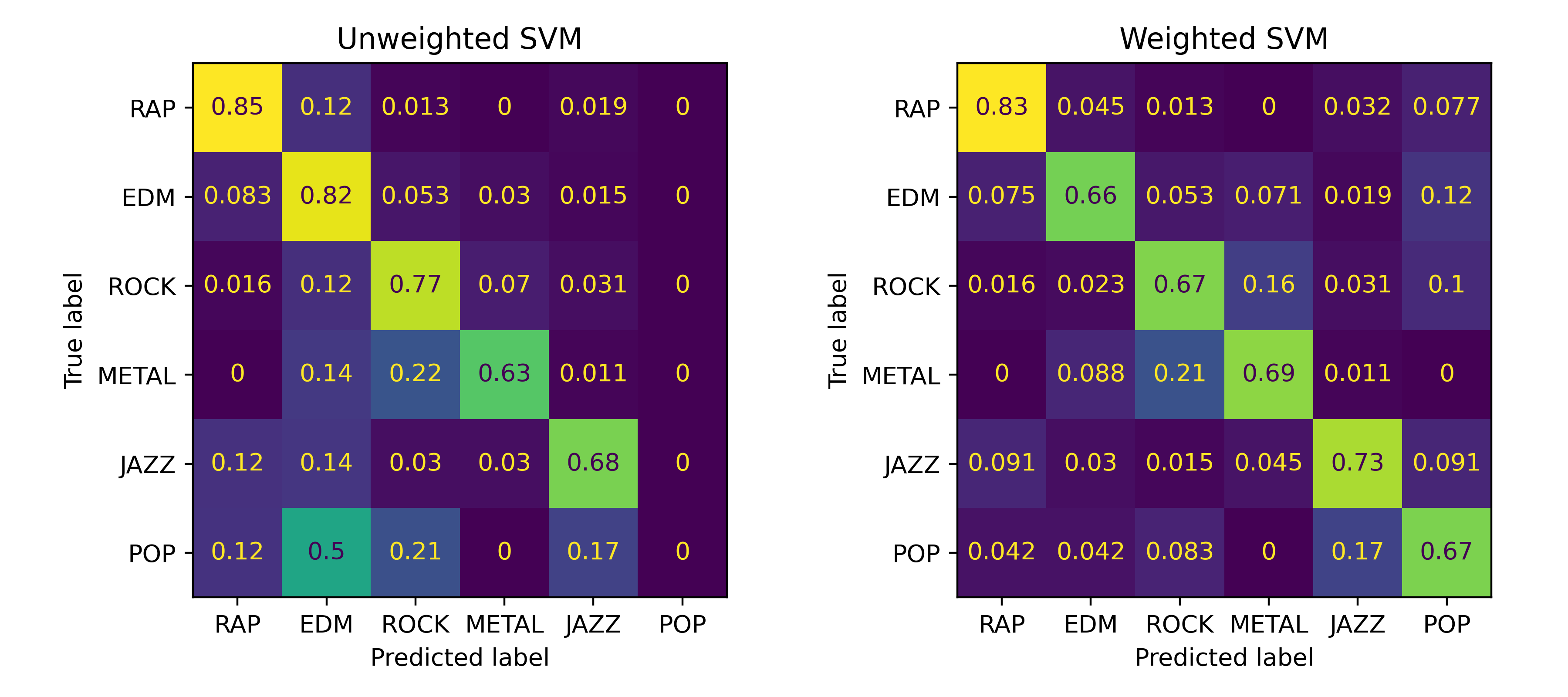
Difference in classification accuracy when weighting the genres based on proportion
There are many ways to begin mitigating this issue. One way is to penalise misclassifying under-represented classes more than the larger ones. This can be implemented in scikit by initialising the model with the class_weight parameter equal to 'balanced'. This was the method used in the matrix on the right, above. It was highly effective in rebalancing the classes, all of them have comparable accuracy afterwards.
Data Stratification Link to heading
Similar to class rebalancing, the dataset also required processing. Before using a model, a dataset is split between a training set and a test set. A default way to do this is to just take a random subset of the data for each set, it is crucial for properly evaluating the model that these datasets are distinct without overlap. However, this doesn’t take into account the relative occurrence of each class in either dataset. For example, a random split could leave more of one class or genre in one dataset than the other. As mentioned, the Pop class is much smaller than the other classes, it is feasible that the whole genre could end up in either the training or test dataset instead of properly splitting.
Instead of allowing this to be determined by a random split, the dataset was stratified when splitting. This applies the given proportion of training to test set to each class during the split such that the same proportion of tracks occur in either dataset.
![]()